
{kind=link}
海量数据热迁移,小程序云开发数据库这样做
前言
随着互联网业务的发展,无论是企业开发者,还是个人开发者,产品能力的不断迭代,都会带来大量的新增数据,数据的新增则意味着作为服务商的云开发需要为开发者们做好数据的存储和备份,以及在合适的时候对集群进行升级、优化。在优化的过程中,就涉及到了迁移的问题。
一般来说,业界针对升级和迁移,会提供热迁移和冷迁移两种方案:
- 冷迁移:冷迁移需要对数据库先进行停机,等迁移完成后,再重启数据库。
- 热迁移:热迁移无需对数据库进行停机,整个迁移过程中,数据库可以持续对外提供服务。用户对于热迁移无感知。用一个比喻来说,就是有一个开着水龙头往里注水的水池,热迁移做的事情是将这个水池子里面的水完整地倒入另外一个水池。

云开发作为基础服务提供商,是无法进行冷迁移的,因此,对于云开发来说,思考如何在现有的架构基础之上做好热迁移势在必行。
云开发数据库架构
想要对云开发的数据库进行热迁移,首先,需要理解云开发数据库的底层架构。
简单来说,云开发的数据库由一组 Keeper 和 Agent 组成的接入层直接对用户提供服务,Keeper 来完成鉴权操作,Agent 负责维护 Keeper 到底层数据库的链接池,用户的请求会打散并分发到各个 Agent 中,避免单点数据故障。
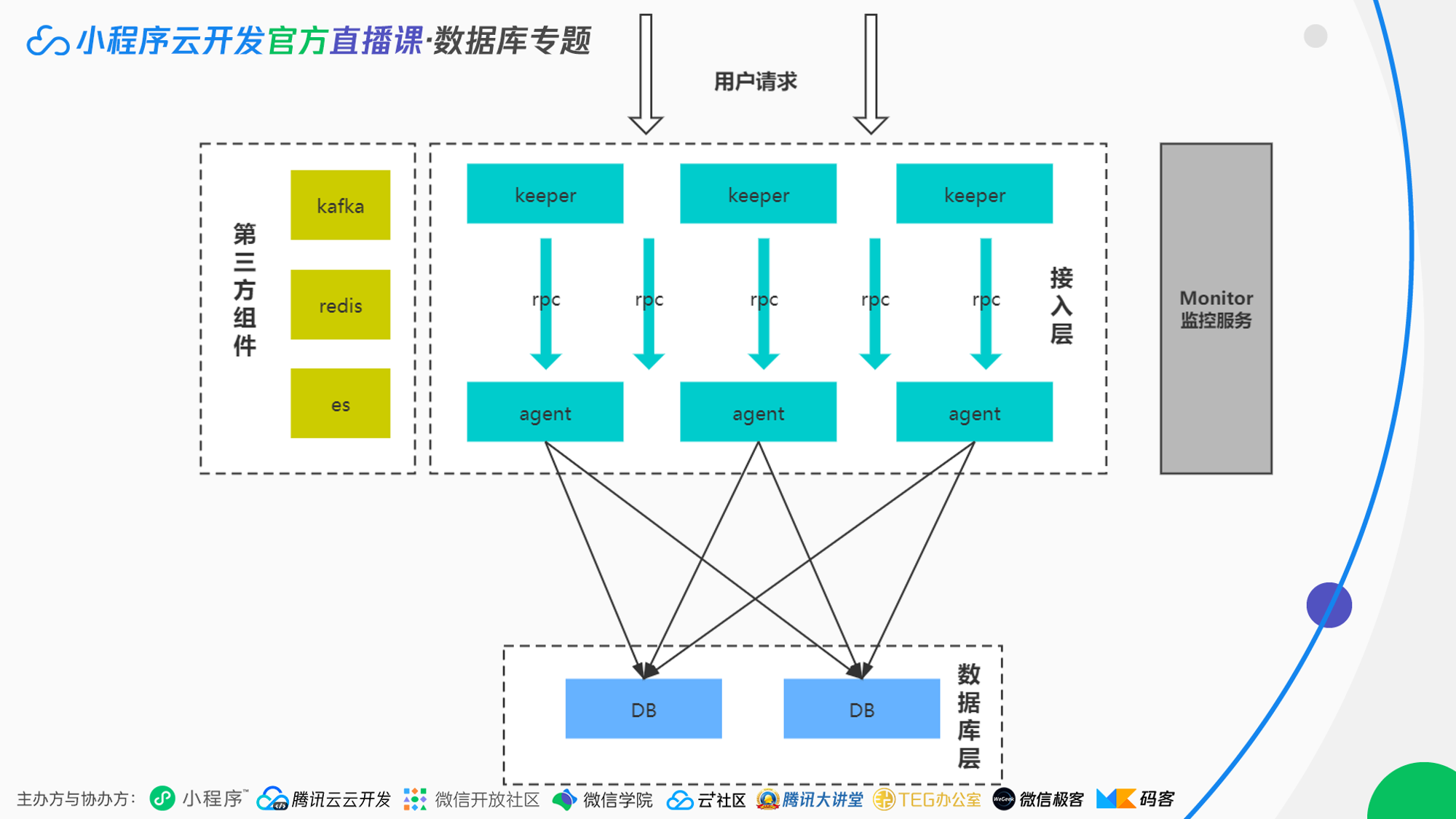
就云开发本身的数据实现而言,热迁移就意味着在用户请求不停的情况下,将用户的存储集群从 db1 迁移至 db2,并将 agent 的连接池从 db1 指向 db2。
如何实现热迁移?
在了解了云开发底层的数据库架构以后,就可以来讨论迁移的具体实现。
热迁移的基础是数据库底层的迁移能力,而数据库底层的迁移分为三个状态:
- 数据同步:对快照和数据库的 oplog 进行拷贝和追踪;
- 数据割接:在 oplog 几乎追上时,进行数据割接;
- 目标集群可用:完成割接后,原集群变为可用状态。
可以看到,在这个过程中,割接会影响原集群的读写状态,所以对于热迁移来说,割接的处理至关重要。我们需要在割接过程中 block 住用户的请求,在割接完成之后将请求转发到新的集群,同时我们需要尽量保证割接的时间不能太长。

类似的,也因为割接的重要性,引出了热迁移的四个难点:
- 强一致性地感知集群变更、热迁移状态:热迁移完成后,agent 需要改变连接池指向;
- 高性能割接
- 割接状态持久化,超时控制 :割接过程的容灾处理;
- 割接流程中 block 住用户请求的能力:通过 block 用户请求,实现无损热迁移。
在对于热迁移的难点有了深入的理解后,我们设计了如下的热迁移实现流程:
图中的 DBMaster 为云开发数据库底层数据库控制中心;Shark 为接入层控制服务、Agent 为接入层;ETCD 为分布式键值存储系统,用于配置共享和服务发现。
第一步:发起请求:由 shark 向 db master 发起开始热迁移的请求;
第二步:数据同步:db maste 响应 response,同时开始数据同步,此时原集群可写可读;
第三步:数据割接:数据同步完成之后 db master 判断可以进行割接了,于是发起开始割接请求,shark 向 etcd 中写入割接信息;
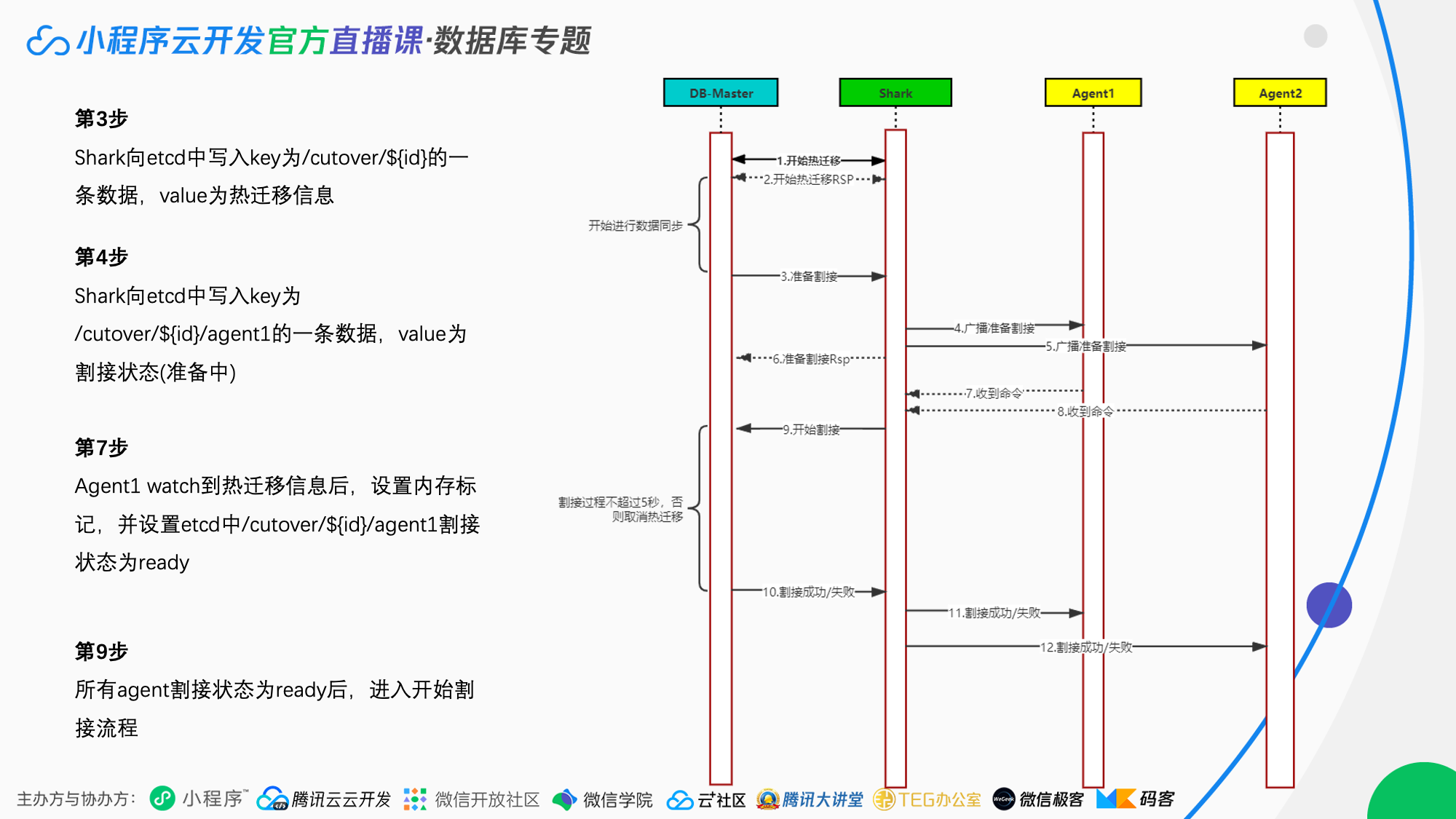
第四、五步:广播请求:shark 广播准备割接请求到全部的 agent;
第六步:回复请求:shark 回复准备割接 response;
第七、八步:Block 请求:agent 收到消息之后,设置 etcd 中的割接状态,相当于回复一个 ack。此时 agent 开始准备 block 住用户的请求;
第九步:调整割接状态:通知 db master 进行割接,整个割接状态不超过 5 秒,通过 etcd 超时实现;
第十步:确认状态:db master 回复割接成功或者失败的 response;
第十一、十二步:通知割接成功:shark 通知各个 agent 本次割接是否成功。
通过上述操作,即可成功的完成云开发数据库的热迁移。值得注意的是,在割接过程中,被迁移数据库的连接池是被 block 住的,直到割接流程结束,因此,整个割接的过程需要尽可能的短,以免影响用户请求。
数据分析
我们基于上述的方案,做了一些测试,在测试环境 3KQPS 写请求的情况下,用户请求无失败。
生产环境下目前迁移用户请求如图所示:

以上便是基于小程序云开发自身的数据库架构设计的数据库底层热迁移实现方案概述。